Map接口
Map接口与List、Set接口不同,它是由一系列键值对组成的集合,提供了key到value的映射,在Map中,它保证了key和value之间的一一对应关系。Map接口定义了一个类似于“字典”的规范,让我们能够根据键快速检索到它所关联的值。
|
|
Map接口的具体实现类主要有HashMap,LinkedHashMap,TreeMap,HashTable,AbstractMap,EnumMap。

HashMap实现原理
以哈希表数据结构实现,查找对象时通过哈希函数计算其位置,它是为快速查询而设计的,其内部定义了一个hash表数组(Entry[] table),元素会通过哈希转换函数将元素的哈希地址转换成数组中存放的索引,如果有冲突,则使用散列链表的形式将所有相同哈希地址的元素串起来,可以通过查看HashMap.Entry的源码它是一个单链表结构。
HashMap实际上是一个链表散列的数据结构,即数组和链表的结构,但是在jdk1.8里加入了红黑树的实现,当链表的长度大于8的时候,就会转换为红黑树的结构。HashMap的数据结构如下图所示。
从上图中可以知道,Java中HashMap采用了链地址法,即数组加链表的结合,在每个数组元素上都是一个链表结构,当数据被hash后,得到数组下标,把数据放在对应下标元素的链表上。下面是HashMap数据结构的源码实现。
123456789101112131415161718192021222324252627282930313233343536373839404142public class HashMap<K, V> extends AbstractMap<K, V>implements Map<K, V>, Cloneable, Serializable {...static final int TREEIFY_THRESHOLD = 8;transient HashMap.Node<K, V>[] table;...public HashMap(int var1, float var2) {if(var1 < 0) {throw new IllegalArgumentException("Illegal initial capacity: " + var1);} else {if(var1 > 1073741824) {var1 = 1073741824;}if(var2 > 0.0F && !Float.isNaN(var2)) {this.loadFactor = var2;this.threshold = tableSizeFor(var1);} else {throw new IllegalArgumentException("Illegal load factor: " + var2);}}}public HashMap(int var1) {this(var1, 0.75F);}public HashMap() {this.loadFactor = 0.75F;}public HashMap(Map<? extends K, ? extends V> var1) {this.loadFactor = 0.75F;this.putMapEntries(var1, false);}public V put(K var1, V var2) {// 这个方法调用了putVal()方法,putVal()方法在table数组为初始化情况下,默认创建一个容量大小为16 的Node数组并赋值给table数组。return this.putVal(hash(var1), var1, var2, false, true);}...}1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950static class Node<K, V> implements Entry<K, V> {final int hash; // 用于定位数组索引的位置final K key;V value;HashMap.Node<K, V> next; // 链表的下一个NodeNode(int var1, K var2, V var3, HashMap.Node<K, V> var4) {this.hash = var1;this.key = var2;this.value = var3;this.next = var4;}public final K getKey() {return this.key;}public final V getValue() {return this.value;}public final String toString() {return this.key + "=" + this.value;}public final int hashCode() {return Objects.hashCode(this.key) ^ Objects.hashCode(this.value);}public final V setValue(V var1) {Object var2 = this.value;this.value = var1;return var2;}public final boolean equals(Object var1) {if(var1 == this) {return true;} else {if(var1 instanceof Entry) {Entry var2 = (Entry)var1;if(Objects.equals(this.key, var2.getKey()) && Objects.equals(this.value, var2.getValue())) {return true;}}return false;}}}Node是HashMap的一个内部类,实现了Map.Entry接口,本质上就是一个映射(键值对)。
有时两个key会定位到相同的位置,表示发生了hash碰撞,当然hash算法计算结果越分散均匀,hash碰撞的概率就越小,map的存取效率就会越高。
HashMap类中有一个非常重要的字段,就是 Node[] table,即哈希桶数组,明显它是一个Node的数组。Node[] table的初始化长度length(jdk源码中默认值是16, android源码中初始值是8),Load factor为负载因子(默认值是0.75),threshold是HashMap所能容纳的最大数据量的Node(键值对)个数。threshold = length * Load factor。也就是说,在数组定义好长度之后,负载因子越大,所能容纳的键值对个数越多。
结合负载因子的定义公式可知,threshold就是在此Load factor和length(数组长度)对应下允许的最大元素数目,超过这个数目就重新resize(扩容),扩容后的HashMap容量是之前容量的两倍。在HashMap中,哈希桶数组table的长度length大小必须为2的n次方。
接下来看看table怎样确定索引位置。
1234567891011//方法一:static final int hash(Object key) { //jdk1.8 & jdk1.7int h;// h = key.hashCode() 为第一步 取hashCode值// h ^ (h >>> 16) 为第二步 高位参与运算return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}//方法二:static int indexFor(int h, int length) { //jdk1.7的源码,jdk1.8没有这个方法,但是实现原理一样的return h & (length-1); //第三步 取模运算}这里的Hash算法本质上就是三步:取key的hashCode值、高位运算、取模运算。
接着看一下HashMap最关键的两个方法put()和get()的实现。
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374public V put(K var1, V var2) {return this.putVal(hash(var1), var1, var2, false, true);}final V putVal(int var1, K var2, V var3, boolean var4, boolean var5) {HashMap.Node[] var6 = this.table;int var8;if(this.table == null || (var8 = var6.length) == 0) {var8 = (var6 = this.resize()).length;}Object var7;int var9;if((var7 = var6[var9 = var8 - 1 & var1]) == null) {var6[var9] = this.newNode(var1, var2, var3, (HashMap.Node)null);} else {Object var10;label79: {Object var11;if(((HashMap.Node)var7).hash == var1) {var11 = ((HashMap.Node)var7).key;if(((HashMap.Node)var7).key == var2 || var2 != null && var2.equals(var11)) {var10 = var7;break label79;}}if(var7 instanceof HashMap.TreeNode) {var10 = ((HashMap.TreeNode)var7).putTreeVal(this, var6, var1, var2, var3);} else {int var12 = 0;while(true) {var10 = ((HashMap.Node)var7).next;if(((HashMap.Node)var7).next == null) {((HashMap.Node)var7).next = this.newNode(var1, var2, var3, (HashMap.Node)null);if(var12 >= 7) {this.treeifyBin(var6, var1);}break;}if(((HashMap.Node)var10).hash == var1) {var11 = ((HashMap.Node)var10).key;if(((HashMap.Node)var10).key == var2 || var2 != null && var2.equals(var11)) {break;}}var7 = var10;++var12;}}}if(var10 != null) {Object var13 = ((HashMap.Node)var10).value;if(!var4 || var13 == null) {((HashMap.Node)var10).value = var3;}this.afterNodeAccess((HashMap.Node)var10);return var13;}}++this.modCount;if(++this.size > this.threshold) {this.resize();}this.afterNodeInsertion(var5);return null;}put()方法大致的思路为:
①对key的hashCode()做hash,然后再计算index。
②如果没有碰撞直接放到table里。
③如果碰撞了,以链表的形式存放在table后。
④如果碰撞导致链表过长(大于等于TREEIFY_THRESHOLD),就把链表转换为红黑树。
⑤如果节点已经存在就替换old value(保证key的唯一性)
⑥如果table满了(超过load factor * current capacity),就要resize()。
1234567891011121314151617181920212223242526272829303132333435363738public V get(Object var1) {HashMap.Node var2;return (var2 = this.getNode(hash(var1), var1)) == null?null:var2.value;}final HashMap.Node<K, V> getNode(int var1, Object var2) {HashMap.Node[] var3 = this.table;HashMap.Node var4;int var6;if(this.table != null && (var6 = var3.length) > 0 && (var4 = var3[var6 - 1 & var1]) != null) {Object var7;if(var4.hash == var1) {var7 = var4.key;if(var4.key == var2 || var2 != null && var2.equals(var7)) {return var4;}}HashMap.Node var5 = var4.next;if(var4.next != null) {// 树if(var4 instanceof HashMap.TreeNode) {return ((HashMap.TreeNode)var4).getTreeNode(var1, var2);}// 链表do {if(var5.hash == var1) {var7 = var5.key;if(var5.key == var2 || var2 != null && var2.equals(var7)) {return var5;}}} while((var5 = var5.next) != null);}}return null;}get()方法大致思路为:
①table里面的第一个节点,直接命中。
②如果有冲突,就通过key.equals(k)去查找对应的entry,若为树,则在树中通过key.equals(k)查找,耗时O(logn),若为链表,则在链表中通过key.equals(k)查找,耗时O(n)。
HashMap不是线程安全的,因此如果在使用迭代器的过程中有其他线程修改了map,那么将抛出ConcurrentModificationException,即所谓的fail-fast策略。
LinkedHashMap实现原理
LinkedHashMap是HashMap的一个子类,它保留插入的顺序,如果需要输出的顺序和输入时的相同,那么就选用LinkedHashMap。LinkedHashMap是Map接口的哈希表和链接列表实现,具有可预知的迭代顺序。此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。LinkedHashMap实现与HashMap的不同之处在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。根据链表中元素的顺序可以分为:按插入顺序的链表,和按访问顺序(调用get方法)的链表。默认是按插入顺序排序,如果指定按访问顺序排序,那么调用get方法后,会将这次访问的元素移至链表尾部,不断访问可以形成按访问顺序排序的链表。
接下来看一下LinkedHashMap的数据结构图。
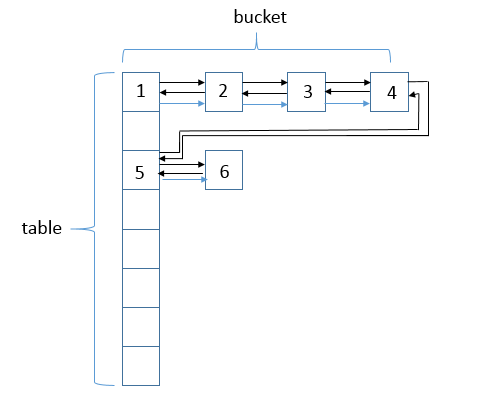
LinkedHashMap会将元素串起来,形成一个双链表结构。可以看到,其结构在HashMap结构上增加了链表结构。数据结构为(数组 + 单链表 + 红黑树 + 双链表),图中的标号是结点插入的顺序。
接下来看看LinkedHashMap数据结构的源码实现。
1234567891011121314151617181920212223242526272829303132333435363738394041public class LinkedHashMap<K, V> extends HashMap<K, V> implements Map<K, V> {private static final long serialVersionUID = 3801124242820219131L;transient LinkedHashMap.Entry<K, V> head; // 链表头结点transient LinkedHashMap.Entry<K, V> tail; // 链表尾节点final boolean accessOrder; // 存储顺序(accessOrder = false)// 访问顺序(accessOrder = true)...public LinkedHashMap(int var1, float var2) {super(var1, var2);this.accessOrder = false;}public LinkedHashMap(int var1) {super(var1);this.accessOrder = false;}public LinkedHashMap() {this.accessOrder = false;}public LinkedHashMap(Map<? extends K, ? extends V> var1) {this.accessOrder = false;this.putMapEntries(var1, false);}public LinkedHashMap(int var1, float var2, boolean var3) {super(var1, var2);this.accessOrder = var3;}...static class Entry<K, V> extends Node<K, V> {// 在HashMap.Node基础上增加了前后两个指针域,同时HashMap.Node中的next域也存在LinkedHashMap.Entry<K, V> before;LinkedHashMap.Entry<K, V> after;Entry(int var1, K var2, V var3, Node<K, V> var4) {super(var1, var2, var3, var4);}}}LinkedHashMap的核心就是存在存储顺序(accessOrder = false)和访问顺序(accessOrder = true),主要是由双向链表来维护顺序。
1234567891011121314public V get(Object var1) {Node var2;// 默认是存储顺序,getNode()方法继承了父类HashMap的getNode()方法if((var2 = this.getNode(hash(var1), var1)) == null) {return null;} else {if(this.accessOrder) {// 当accessOrder == true的时候,是访问顺序的迭代查找this.afterNodeAccess(var2);}// 当accessOrder == false的时候,是存储顺序的迭代查找return var2.value;}}下面主要看访问顺序的,存储顺序不再赘述。
123456789101112131415161718192021222324252627282930313233void afterNodeAccess(Node<K, V> var1) {if(this.accessOrder) {LinkedHashMap.Entry var2 = this.tail;if(this.tail != var1) {LinkedHashMap.Entry var3 = (LinkedHashMap.Entry)var1;LinkedHashMap.Entry var4 = var3.before;LinkedHashMap.Entry var5 = var3.after;var3.after = null;if(var4 == null) {this.head = var5;} else {var4.after = var5;}if(var5 != null) {var5.before = var4;} else {var2 = var4;}if(var2 == null) {this.head = var3;} else {var3.before = var2;var2.after = var3;}this.tail = var3;++this.modCount;}}}此函数在很多函数(如put)中都会被回调,LinkedHashMap重写了HashMap中的此函数。若访问顺序为true,且访问的对象不是尾结点,则下面的图展示了访问前和访问后的状态,假设访问的结点为结点3。

从图中可以看到,结点3链接到了尾结点后面。
TreeMap实现原理
TreeMap 是一个有序的key-value集合,非同步,基于红黑树(Red-Black tree)实现,每一个key-value节点作为红黑树的一个节点。TreeMap存储时会进行排序的,会根据key来对key-value键值对进行排序,其中排序方式也是分为两种,一种是自然排序,一种是定制排序,具体取决于使用的构造方法。
自然排序:TreeMap中所有的key必须实现Comparable接口,并且所有的key都应该是同一个类的对象,否则会报ClassCastException异常。
定制排序:定义TreeMap时,创建一个comparator对象,该对象对所有的treeMap中所有的key值进行排序,采用定制排序的时候不需要TreeMap中所有的key必须实现Comparable接口。
TreeMap数据结构的源码实现如下。
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061public class TreeMap<K, V> extends AbstractMap<K, V>implements NavigableMap<K, V>, Cloneable, Serializable {private final Comparator<? super K> comparator; // 比较器,对TreeMap内部排序进行精密的控制private transient TreeMap.Entry<K, V> root; // TreeMap红-黑节点,为TreeMap的内部类private transient int size = 0; // 容量大小private transient int modCount = 0; // TreeMap修改次数private transient TreeMap<K, V>.EntrySet entrySet;private transient TreeMap.KeySet<K> navigableKeySet;private transient NavigableMap<K, V> descendingMap;private static final Object UNBOUNDED = new Object();private static final boolean RED = false; // 红黑树的节点颜色——红色private static final boolean BLACK = true; // 红黑树的节点颜色——黑色...static final class Entry<K, V> implements java.util.Map.Entry<K, V> {K key;V value;TreeMap.Entry<K, V> left;TreeMap.Entry<K, V> right;TreeMap.Entry<K, V> parent;boolean color = true;Entry(K var1, V var2, TreeMap.Entry<K, V> var3) {this.key = var1;this.value = var2;this.parent = var3;}public K getKey() {return this.key;}public V getValue() {return this.value;}public V setValue(V var1) {Object var2 = this.value;this.value = var1;return var2;}public boolean equals(Object var1) {if(!(var1 instanceof java.util.Map.Entry)) {return false;} else {java.util.Map.Entry var2 = (java.util.Map.Entry)var1;return TreeMap.valEquals(this.key, var2.getKey()) && TreeMap.valEquals(this.value, var2.getValue());}}public int hashCode() {int var1 = this.key == null?0:this.key.hashCode();int var2 = this.value == null?0:this.value.hashCode();return var1 ^ var2;}public String toString() {return this.key + "=" + this.value;}}}接下来看一下TreeMap的关键方法put()和delete(),通过这两个方法可以了解红黑树增加、删除节点的核心算法。
TreeMap put()方法实现分析
在TreeMap的put()的实现方法中主要分为两个步骤,第一,构建排序二叉树,第二,平衡二叉树。
对于排序二叉树的创建,其添加节点的过程如下:
① 以根节点为初始节点进行检索。
② 与当前节点进行比对,若新增节点值较大,则以当前节点的右子节点作为新的当前节点。否则以当前节点的左子节点作为新的当前节点。
③ 循环递归2步骤知道检索出合适的叶子节点为止。
④ 将新增节点与3步骤中找到的节点进行比对,如果新增节点较大,则添加为右子节点;否则添加为左子节点。
下一步就是要进行调整,调整的过程务必会涉及到红黑树的左旋、右旋、着色三个基本操作。
以下是源码实现。
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061public V put(K var1, V var2) {TreeMap.Entry var3 = this.root;if(var3 == null) {this.compare(var1, var1);this.root = new TreeMap.Entry(var1, var2, (TreeMap.Entry)null);this.size = 1;++this.modCount;return null;} else {Comparator var6 = this.comparator;int var4;TreeMap.Entry var5;if(var6 != null) {do {var5 = var3;var4 = var6.compare(var1, var3.key);if(var4 < 0) {var3 = var3.left;} else {if(var4 <= 0) {return var3.setValue(var2);}var3 = var3.right;}} while(var3 != null);} else {if(var1 == null) {throw new NullPointerException();}Comparable var7 = (Comparable)var1;// 构建排序二叉树do {var5 = var3;var4 = var7.compareTo(var3.key);if(var4 < 0) {var3 = var3.left;} else {if(var4 <= 0) {return var3.setValue(var2);}var3 = var3.right;}} while(var3 != null);}TreeMap.Entry var8 = new TreeMap.Entry(var1, var2, var5);if(var4 < 0) {var5.left = var8;} else {var5.right = var8;}// 平衡二叉树this.fixAfterInsertion(var8);++this.size;++this.modCount;return null;}}1234567891011121314151617181920212223242526272829303132333435363738394041424344private void fixAfterInsertion(TreeMap.Entry<K, V> var1) {var1.color = false;while(var1 != null && var1 != this.root && !var1.parent.color) {TreeMap.Entry var2;if(parentOf(var1) == leftOf(parentOf(parentOf(var1)))) {var2 = rightOf(parentOf(parentOf(var1)));if(!colorOf(var2)) {setColor(parentOf(var1), true);setColor(var2, true);setColor(parentOf(parentOf(var1)), false);var1 = parentOf(parentOf(var1));} else {if(var1 == rightOf(parentOf(var1))) {var1 = parentOf(var1);this.rotateLeft(var1);}setColor(parentOf(var1), true);setColor(parentOf(parentOf(var1)), false);this.rotateRight(parentOf(parentOf(var1)));}} else {var2 = leftOf(parentOf(parentOf(var1)));if(!colorOf(var2)) {setColor(parentOf(var1), true);setColor(var2, true);setColor(parentOf(parentOf(var1)), false);var1 = parentOf(parentOf(var1));} else {if(var1 == leftOf(parentOf(var1))) {var1 = parentOf(var1);this.rotateRight(var1);}setColor(parentOf(var1), true);setColor(parentOf(parentOf(var1)), false);this.rotateLeft(parentOf(parentOf(var1)));}}}this.root.color = true;}TreeMap delete()方法分析
确认删除节点的步骤是:找到一个替代子节点C来替代P,然后直接删除C,最后调整这棵红黑树。
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849private void deleteEntry(TreeMap.Entry<K, V> var1) {++this.modCount;--this.size;TreeMap.Entry var2;if(var1.left != null && var1.right != null) {// 寻找P的替代节点var2 = successor(var1);var1.key = var2.key;var1.value = var2.value;var1 = var2;}var2 = var1.left != null?var1.left:var1.right;// 删除节点,主要有三种情况,分别是有0、1、2个子节点的情况。if(var2 != null) {var2.parent = var1.parent;if(var1.parent == null) {this.root = var2;} else if(var1 == var1.parent.left) {var1.parent.left = var2;} else {var1.parent.right = var2;}var1.left = var1.right = var1.parent = null;if(var1.color) {// 调整红黑树this.fixAfterDeletion(var2);}} else if(var1.parent == null) {this.root = null;} else {if(var1.color) {// 调整红黑树this.fixAfterDeletion(var1);}if(var1.parent != null) {if(var1 == var1.parent.left) {var1.parent.left = null;} else if(var1 == var1.parent.right) {var1.parent.right = null;}var1.parent = null;}}}寻找替代节点,其实现方法为successor(),如下。
12345678910111213141516171819202122static <K, V> TreeMap.Entry<K, V> successor(TreeMap.Entry<K, V> var0) {if(var0 == null) {return null;} else {TreeMap.Entry var1;if(var0.right != null) {for(var1 = var0.right; var1.left != null; var1 = var1.left) {;}return var1;} else {var1 = var0.parent;for(TreeMap.Entry var2 = var0; var1 != null && var2 == var1.right; var1 = var1.parent) {var2 = var1;}return var1;}}}删除完节点后,就要根据情况来对红黑树进行复杂的调整:fixAfterDeletion()实现如下。
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960private void fixAfterDeletion(TreeMap.Entry<K, V> var1) {while(var1 != this.root && colorOf(var1)) {TreeMap.Entry var2;if(var1 == leftOf(parentOf(var1))) {var2 = rightOf(parentOf(var1));if(!colorOf(var2)) {setColor(var2, true);setColor(parentOf(var1), false);this.rotateLeft(parentOf(var1));var2 = rightOf(parentOf(var1));}if(colorOf(leftOf(var2)) && colorOf(rightOf(var2))) {setColor(var2, false);var1 = parentOf(var1);} else {if(colorOf(rightOf(var2))) {setColor(leftOf(var2), true);setColor(var2, false);this.rotateRight(var2);var2 = rightOf(parentOf(var1));}setColor(var2, colorOf(parentOf(var1)));setColor(parentOf(var1), true);setColor(rightOf(var2), true);this.rotateLeft(parentOf(var1));var1 = this.root;}} else {var2 = leftOf(parentOf(var1));if(!colorOf(var2)) {setColor(var2, true);setColor(parentOf(var1), false);this.rotateRight(parentOf(var1));var2 = leftOf(parentOf(var1));}if(colorOf(rightOf(var2)) && colorOf(leftOf(var2))) {setColor(var2, false);var1 = parentOf(var1);} else {if(colorOf(leftOf(var2))) {setColor(rightOf(var2), true);setColor(var2, false);this.rotateLeft(var2);var2 = leftOf(parentOf(var1));}setColor(var2, colorOf(parentOf(var1)));setColor(parentOf(var1), true);setColor(leftOf(var2), true);this.rotateRight(parentOf(var1));var1 = this.root;}}}setColor(var1, true);}详细实现原理博客链接:http://blog.csdn.net/chenssy/article/details/26668941
HashTable实现原理
和HashMap一样,Hashtable 也是一个散列表,它存储的内容是键值对(key-value)映射。Hashtable 继承于Dictionary,实现了Map、Cloneable、Serializable接口。Hashtable 的函数都是同步的,这意味着它是线程安全的。它的key、value都不可以为null。此外,Hashtable中的映射不是有序的。
HashTable的数据结构图如下。

HashTable数据结构的源码实现如下。
123456789101112131415161718192021222324public class Hashtable<K, V> extends Dictionary<K, V>implements Map<K, V>, Cloneable, Serializable {private transient Hashtable.Entry<?, ?>[] table;private transient int count;private int threshold;private float loadFactor;private transient int modCount;...private static class Entry<K, V> implements java.util.Map.Entry<K, V> {final int hash;final K key;V value;Hashtable.Entry<K, V> next;protected Entry(int var1, K var2, V var3, Hashtable.Entry<K, V> var4) {this.hash = var1;this.key = var2;this.value = var3;this.next = var4;}...}}HashTable底层使用数组实现,数组中每一项是个单链表,即数组和链表的结合体。
Hashtable在底层将key-value当成一个整体进行处理,这个整体就是一个Entry对象。Hashtable底层采用一个Entry[]数组来保存所有的key-value对,当需要存储一个Entry对象时,会根据key的hash算法来决定其在数组中的存储位置,再根据equals方法决定其在该数组位置上的链表中的存储位置;当需要取出一个Entry时,也会根据key的hash算法找到其在数组中的存储位置,再根据equals方法从该位置上的链表中取出该Entry。
synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,即对每个方法操作都加上了synchronized关键字。
